- Reduce costs by avoiding unnecessary AI provider API calls
- Improve response times by returning cached results instantly
- Maintain consistency for identical or similar queries
- Scale your application more efficiently by reducing API usage
Caching is available for all Neurons, and is free to use. However, the cache is only available for the current deployment of the Neuron. If you deploy a new version of the Neuron with the same slug, the cache will be reset.
Caching Settings
The Caching section of the Neuron Settings page allows you to control how responses are cached and reused.Exact Caching

Exact caching is particularly useful for deterministic operations or when you want to ensure consistent responses for identical inputs. It’s also the fastest and most efficient caching strategy as it completely eliminates API calls for repeated requests.
Semantic Caching
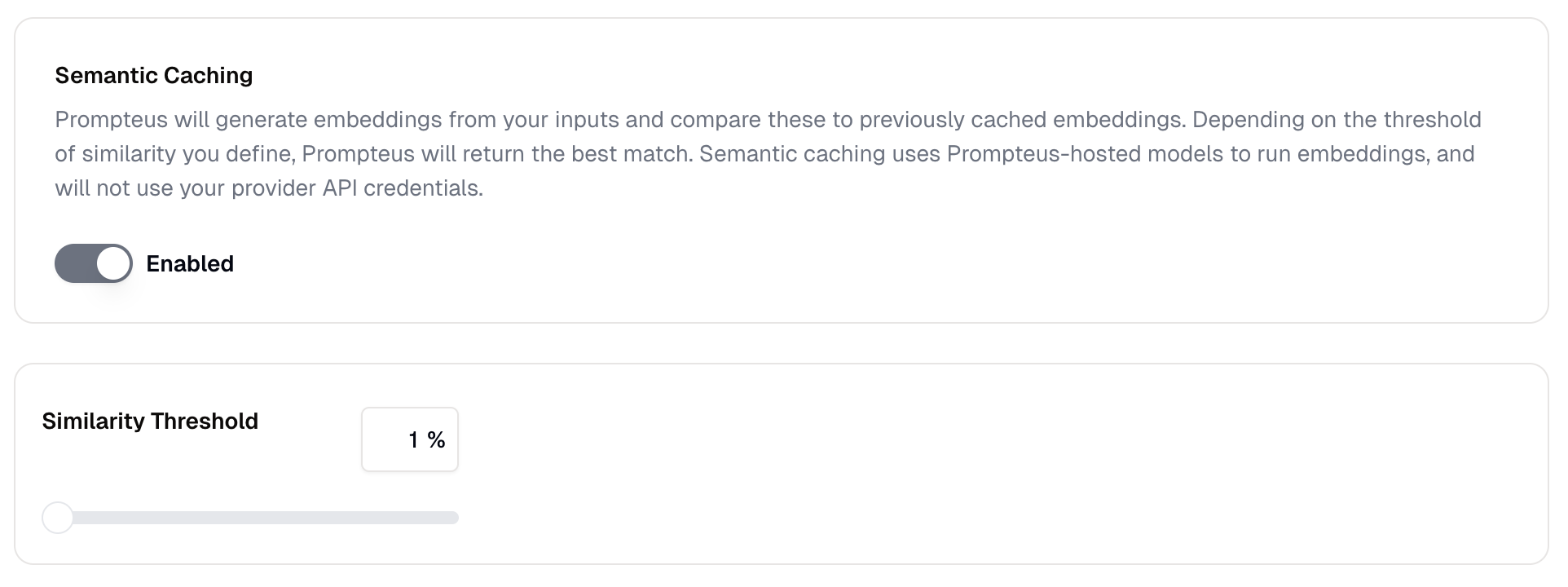
Semantic Caching Similarity Threshold
The similarity threshold determines how similar an input must be to a cached input to trigger a cache hit. The threshold is expressed as a percentage, where:- A higher percentage (e.g., 99%) requires inputs to be nearly identical for a cache hit
- A lower percentage (e.g., 50%) allows for more variation between inputs while still returning cached results
We recommend starting with a high similarity threshold and gradually lowering it based on your specific use case and the observed quality of cached responses.
Cache Duration
Cached responses are stored for a limited time to ensure freshness of data. The exact duration may vary based on your subscription plan and usage patterns. You can bypass the cache for individual requests using thebypassCache parameter when calling the API or SDK. This is useful for testing or when you need to force a fresh response:
Bypassing cache will not purge the cache for the Neuron, only for the specific request. If you need to purge the cache for the Neuron, you can do so by deploying a new version of the Neuron.
Best Practices
Here are some recommendations for effective use of caching:- Enable exact caching for deterministic operations where identical inputs should always produce identical outputs
- Use semantic caching when slight variations in input should still return the same or similar responses
- Adjust the similarity threshold based on your specific use case:
- Higher thresholds for tasks requiring precise matches
- Lower thresholds for more general queries where approximate matches are acceptable
- Monitor cache hit rates and response quality through execution logs to fine-tune your caching settings
- For cost optimization, analyze your most frequent queries and adjust caching settings to maximize cache hits for these high-volume requests